
Education


Experience

I am a professor at School of Cyber Science and Technology, Shandong University. Previously, I was a postdoc at CISPA Helmholtz Center for Information Security, supervised by Dr. Yang Zhang. In Oct 2023, I obtained my Ph.D. from CISPA Helmholtz Center for Information Security, supervised by Dr. Yang Zhang. I received my bachelor (2017) and master (2020) degrees from Shandong University, supervised by Prof. Shanqing Guo.
Research keywords include: Machine learning, Security, Privacy, Safety and so on.
My research focuses on Trustworthy Machine Learning, with an emphasis on identifying and mitigating vulnerabilities in AI systems. I investigate privacy attacks (e.g., membership and attribute inference), security threats (e.g., backdoors and data poisoning), and develop technical defenses against unethical AI deployments.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "News
Research Highlights
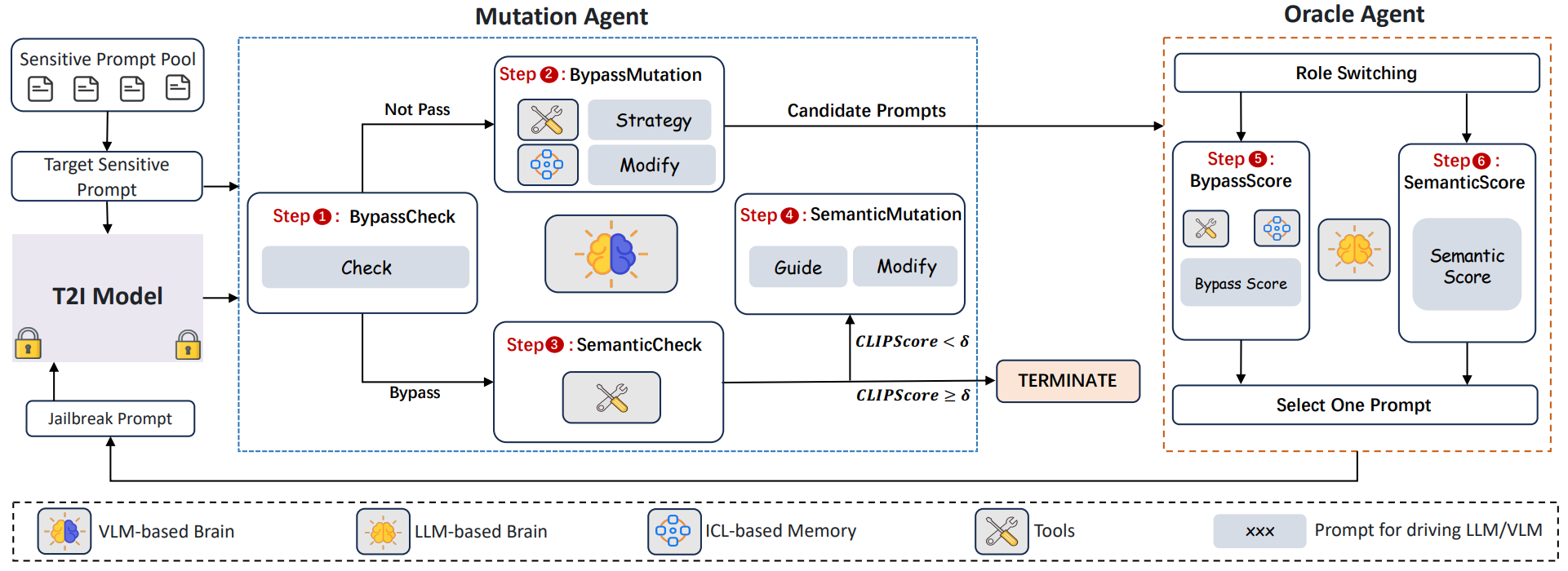
Fuzz-Testing Meets LLM-Based Agents: An Automated and Efficient Framework for Jailbreaking Text-To-Image Generation Models
Yingkai Dong, Xiangtao Meng, Ning Yu, Zheng Li†, Shanqing Guo†
IEEE S&P 2025
Text-to-image (T2I) generative models have revolutionized content creation by transforming textual descriptions into high-quality images. However, these models are vulnerable to jailbreaking attacks, where carefully crafted prompts bypass safety mechanisms to produce unsafe content. While researchers have developed various jailbreak attacks to expose this risk, these methods face significant limitations, including impractical access requirements, easily detectable unnatural prompts, restricted search spaces, and high query demands on the target system. ...
Fuzz-Testing Meets LLM-Based Agents: An Automated and Efficient Framework for Jailbreaking Text-To-Image Generation Models
Yingkai Dong, Xiangtao Meng, Ning Yu, Zheng Li†, Shanqing Guo†
IEEE S&P 2025
Text-to-image (T2I) generative models have revolutionized content creation by transforming textual descriptions into high-quality images. However, these models are vulnerable to jailbreaking attacks, where carefully crafted prompts bypass safety mechanisms to produce unsafe content. While researchers have developed various jailbreak attacks to expose this risk, these methods face significant limitations, including impractical access requirements, easily detectable unnatural prompts, restricted search spaces, and high query demands on the target system. ...

Membership Inference Attacks Against In-Context Learning
Rui Wen, Zheng Li†, Michael Backes, Yang Zhang†
CCS 2024
Adapting Large Language Models (LLMs) to specific tasks introduces concerns about computational efficiency, prompting an exploration of efficient methods such as In-Context Learning (ICL). However, the vulnerability of ICL to privacy attacks under realistic assumptions remains largely unexplored. In this work, we present the first membership inference attack tailored for ICL, relying solely on generated texts without their associated probabilities. We propose four attack strategies tailored to various constrained scenarios and conduct extensive experiments on four popular large language models. ...
Membership Inference Attacks Against In-Context Learning
Rui Wen, Zheng Li†, Michael Backes, Yang Zhang†
CCS 2024
Adapting Large Language Models (LLMs) to specific tasks introduces concerns about computational efficiency, prompting an exploration of efficient methods such as In-Context Learning (ICL). However, the vulnerability of ICL to privacy attacks under realistic assumptions remains largely unexplored. In this work, we present the first membership inference attack tailored for ICL, relying solely on generated texts without their associated probabilities. We propose four attack strategies tailored to various constrained scenarios and conduct extensive experiments on four popular large language models. ...
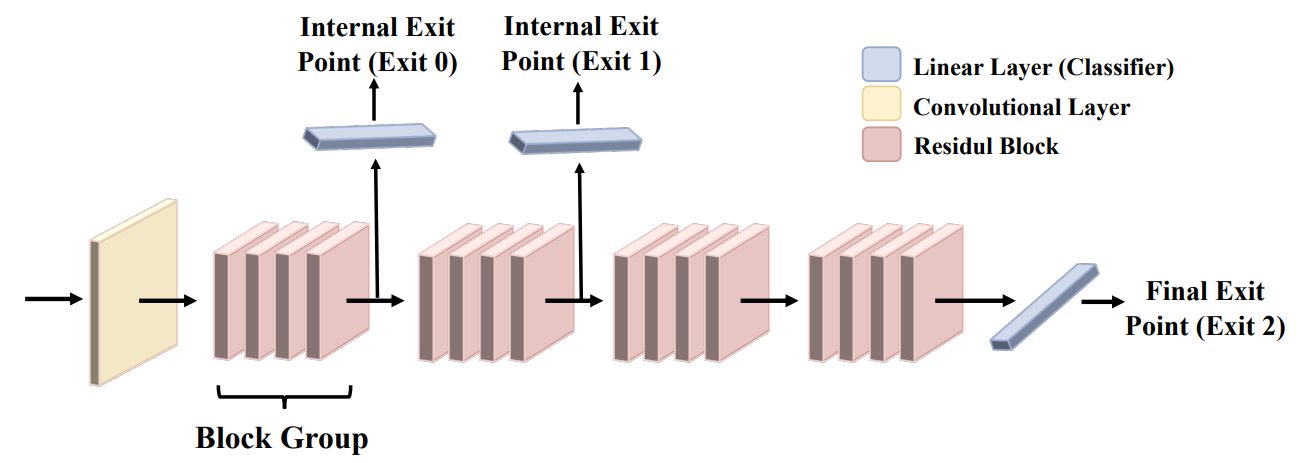
Auditing Membership Leakages of Multi-Exit Networks
Zheng Li, Yiyong Liu, Xinlei He, Ning Yu, Michael Backes, Yang Zhang†
CCS 2022
Relying on the truth that not all inputs require the same level of computational cost to produce reliable predictions, multi-exit networks are gaining attention as a prominent approach for pushing the limits of efficient deployment. Multi-exit networks endow a backbone model with early exits, allowing predictions at intermediate layers of the model and thus saving computation time and energy. However, various current designs of multi-exit networks are only considered to achieve the best trade-off between resource usage efficiency and prediction accuracy, the privacy risks stemming from them have never been explored. This prompts the need for a comprehensive investigation of privacy risks in multi-exit networks. ...
Auditing Membership Leakages of Multi-Exit Networks
Zheng Li, Yiyong Liu, Xinlei He, Ning Yu, Michael Backes, Yang Zhang†
CCS 2022
Relying on the truth that not all inputs require the same level of computational cost to produce reliable predictions, multi-exit networks are gaining attention as a prominent approach for pushing the limits of efficient deployment. Multi-exit networks endow a backbone model with early exits, allowing predictions at intermediate layers of the model and thus saving computation time and energy. However, various current designs of multi-exit networks are only considered to achieve the best trade-off between resource usage efficiency and prediction accuracy, the privacy risks stemming from them have never been explored. This prompts the need for a comprehensive investigation of privacy risks in multi-exit networks. ...
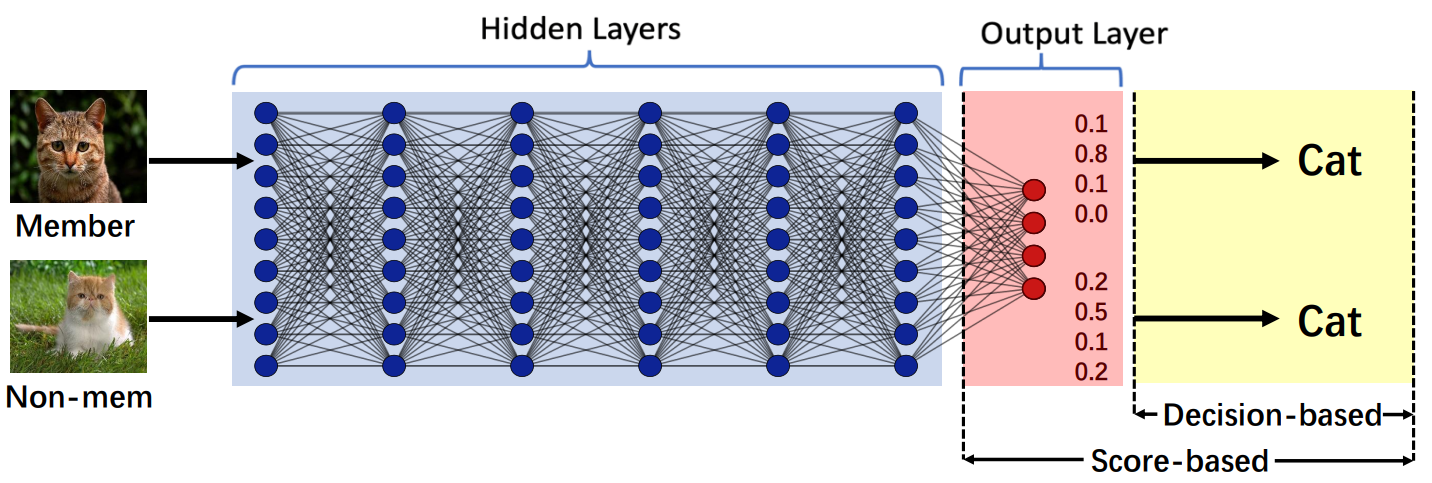
Membership Leakage in Label-Only Exposures
Zheng Li, Yang Zhang†
CCS 2021
Machine learning (ML) has been widely adopted in various privacy-critical applications, e.g., face recognition and medical image analysis. However, recent research has shown that ML models are vulnerable to attacks against their training data. Membership inference is one major attack in this domain: Given a data sample and model, an adversary aims to determine whether the sample is part of the model's training set. Existing membership inference attacks leverage the confidence scores returned by the model as their inputs (score-based attacks). However, these attacks can be easily mitigated if the model only exposes the predicted label, i.e., the final model decision. ...
Membership Leakage in Label-Only Exposures
Zheng Li, Yang Zhang†
CCS 2021
Machine learning (ML) has been widely adopted in various privacy-critical applications, e.g., face recognition and medical image analysis. However, recent research has shown that ML models are vulnerable to attacks against their training data. Membership inference is one major attack in this domain: Given a data sample and model, an adversary aims to determine whether the sample is part of the model's training set. Existing membership inference attacks leverage the confidence scores returned by the model as their inputs (score-based attacks). However, these attacks can be easily mitigated if the model only exposes the predicted label, i.e., the final model decision. ...